
使用concurrent.futures 模块提供的线程池进行并发
concurrent.futures 从python 3.2 版本被加入到发行版中,它提供了线程池和进程池,具有管理并行编程任务、处理非确定性的执行流程、进程/线程同步等功能, 它的submit和map方法可以让你快速的实现多线程并发。
使用线程池,你无需关心线程的创建与销毁,结果的收集,使用起来极为方便,下图是对线程池工作原理的解释
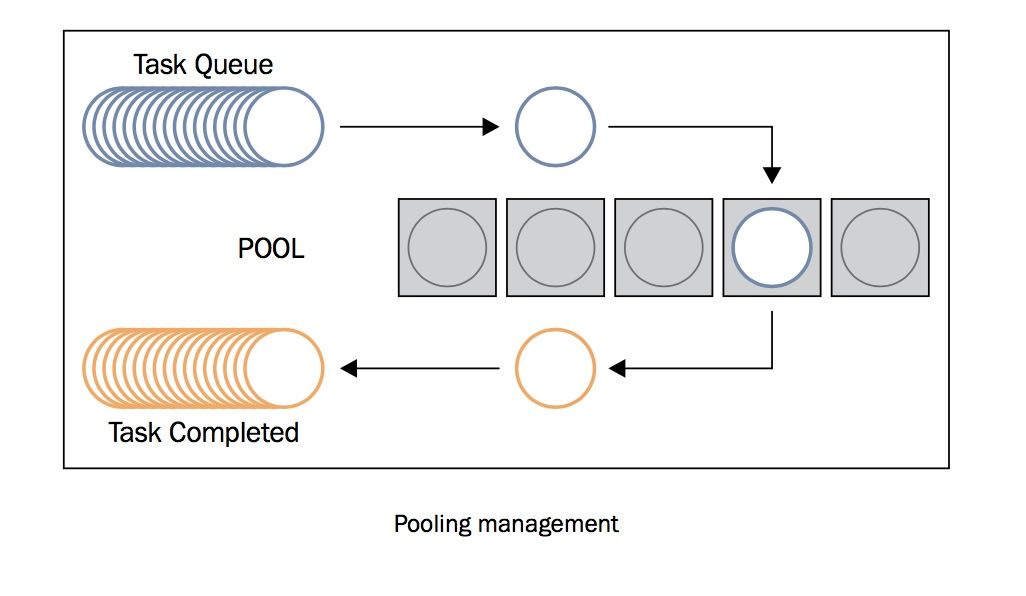
1. 使用submit提交任务到线程池
假设你有1000个url需要进行爬取,这类任务十分适合使用多线程处理。让我们看看使用concurrent.futures 提供的线程池该如何进行并发。
import time
import concurrent.futures
def crawl(url):
"""
爬虫函数, 这里只是模拟爬取过程,耗时0.001秒
:param url:
:return:
"""
time.sleep(0.001)
return url
def thread_pool():
urls = [i for i in range(10000)] # 模拟1000个url
crawl_result = []
with concurrent.futures.ThreadPoolExecutor(max_workers=30) as executor:
futures = [executor.submit(crawl, url) for url in urls]
for future in concurrent.futures.as_completed(futures):
crawl_result.append(future.result())
print(crawl_result[:20])
return crawl_result
if __name__ == '__main__':
thread_pool()
线程池只是提供了并发的机制,你需要自己完成并发时需要调用的函数,这里指的是crawl, 它完成单次任务,爬取一个url并返回结果。
接下来,第1步创建线程池, max_workers 定义了线程池的大小
with concurrent.futures.ThreadPoolExecutor(max_workers=30) as executor:
第2步,向线程池提交任务
futures = [executor.submit(crawl, url) for url in urls]
调用executor 的submit方法,第一个参数是在线程中需要被执行的函数,从第二个参数开始是函数所需要参数。futures 里存储的并不是最终的结果,而是future对象,要等到线程执行函数有了返回值以后才能调用result方法获得返回结果。
第3步,等待返回结果
for future in concurrent.futures.as_completed(futures):
crawl_result.append(future.result())
你不必关系哪个线程完成了一次crawl函数的调用,as_completed方法会帮你识别出已经完成的任务,调用result方法即可获得crawl函数的返回值。
这里要特别强调一点,crawl_result存储的数据与urls 之间是不存在依据索引位置的一一对应关系的,在代码里,我输出了crawl_result前10个元素
[84, 30, 295, 49, 278, 584, 177, 922, 1144, 416, 634, 29, 28, 1026, 294, 277, 176, 583, 1143, 415]
显然,与urls之间毫无关联关系,urls中的0是最先被提交的,但未必是最先完成的,因此这两个列表的索引是不能最为输入与输出之间的映射关系的。如果想要在他们之间建立某个联系,建议在crawl 函数的返回值中加入输入的参数url , 根据这个url 就能够找到对应的urls中的输入信息。
2. 使用map方法并发执行任务
map 与 submit 的最显著的区别在于,map方法返回的结果是有序的
import time
import concurrent.futures
def crawl(url):
"""
爬虫函数, 这里只是模拟爬取过程,耗时0.001秒
:param url:
:return:
"""
time.sleep(0.001)
return url
def thread_pool():
urls = [i for i in range(10000)] # 模拟1000个url
crawl_result = []
with concurrent.futures.ThreadPoolExecutor(max_workers=30) as executor:
res = executor.map(crawl, urls)
crawl_result = list(res)
print(crawl_result[:20])
return crawl_result
if __name__ == '__main__':
thread_pool()
map方法会遍历urls,传入crawl 函数进行调用,返回的结果res是一个生成器,其结果是有序的,使用list方法将生成器转为列表,输出前20个元素
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
这与urls的前20个元素是一一对应的。

扫描关注, 与我技术互动
QQ交流群: 211426309
